Dein AI Agent, jeden Tag schärfer
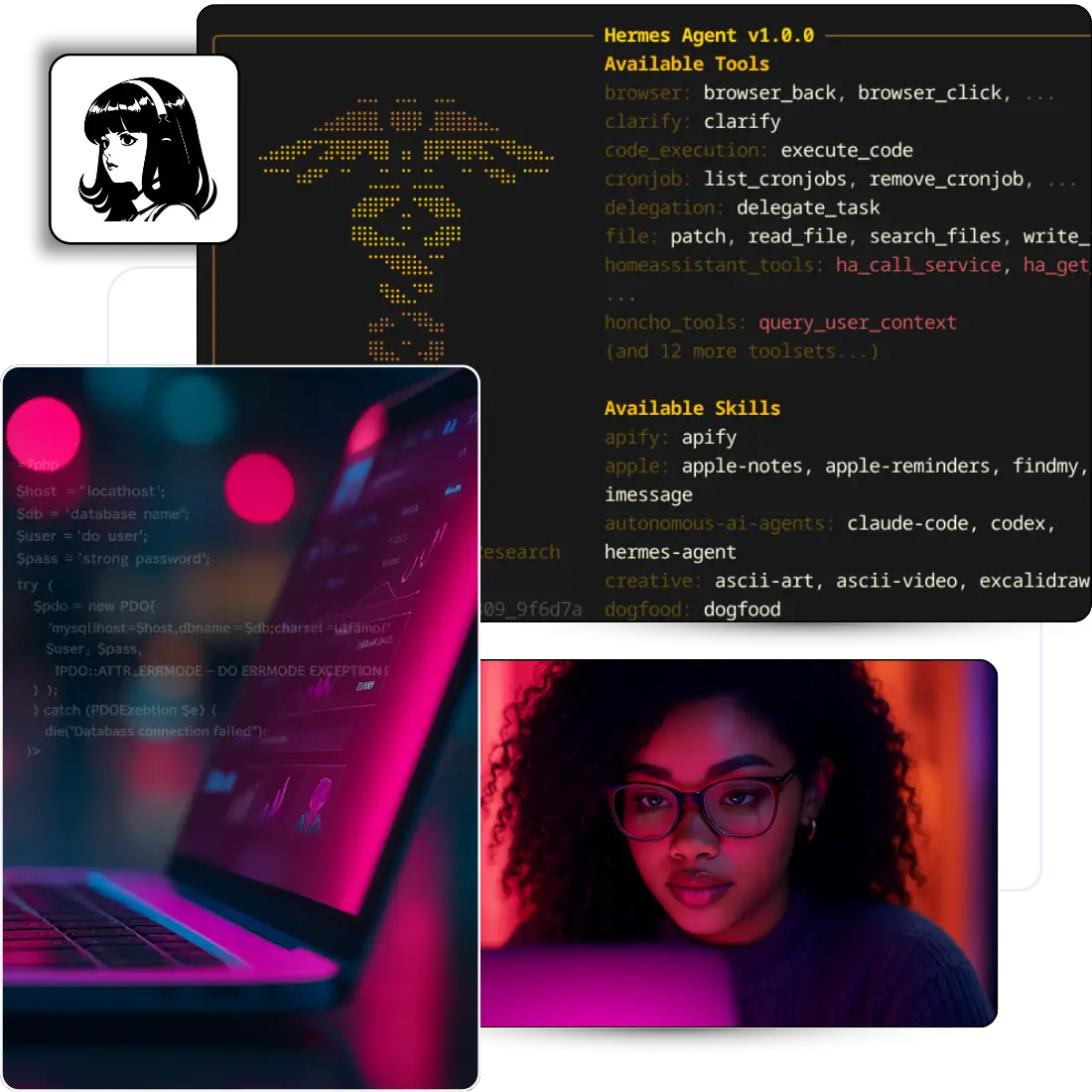
Hermes Agent ist die Open-Source-AI-Runtime von Nous Research. Du zeigst ihn auf jedes LLM, das du magst (Nous Portal, OpenAI Codex, Anthropic, OpenRouter, GLM, DeepSeek, lokale Ollama-Modelle und 15+ weitere), und der Agent wird mit der Zeit schärfer, weil die Learning Loop wiederkehrende Aufgaben in wiederverwendbare Skills verwandelt, die unter ~/.hermes/skills/ abgelegt werden.
Hermes auf einem VPS hält den Agent rund um die Uhr online. Der Speicher bleibt zwischen Sessions erhalten, geplante Jobs laufen weiter, egal ob du am Schreibtisch sitzt oder schläfst, und du bestimmst, welche Modelle, Gateways oder Integrationen tatsächlich laufen. MIT-Lizenz, null Telemetrie und keine Plattform, die deinem Agent vorschreibt, was er darf.

















.svg)
.svg)
.svg)
.svg)
.svg)
.svg)
.svg)

.svg)
.svg)
.svg)
.svg)
.svg)




















.png)









